SVM簡單說明
為一種監督學習的方法,其原理是會根據資料的數據,劃出一條界線來區分各群
我舉個例子說明:
假如我們今天有一個任務,是要區分此生物是否為海洋生物
我們把海平面以下的生物都當作是海洋生物,海平面以上則否
海平面這個界線就是我們SVM的訓練結果,此界線就是我們拿來分群的標準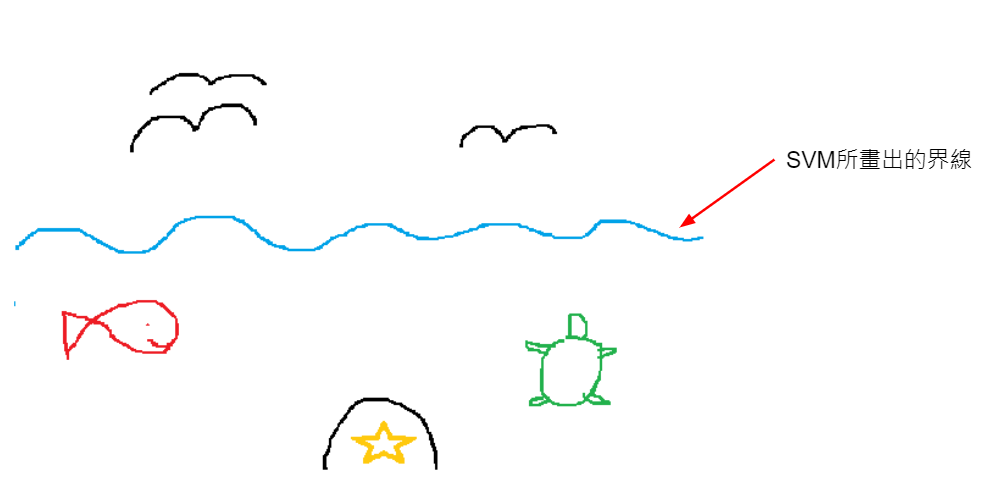
我只是以2維平面的方式來比喻,真正我們在訓練時,資料維度都很高,所以無法圖像化
反正我們知道其原理就好了
使用方法
這邊我使用的資料集為Titanic
前處理我直接跟Day24、25、26的一樣,如果想了解可以去看前面的文章
import SVM
from sklearn import svm
自己先設一個變數,此變數為你的model名稱,並將svm.LinearSVC()指派給它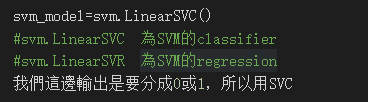
訓練model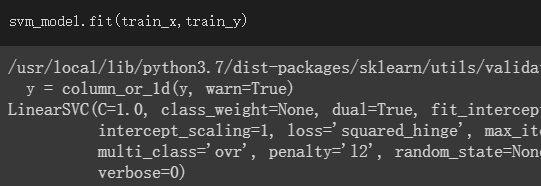
查看訓練結果的成績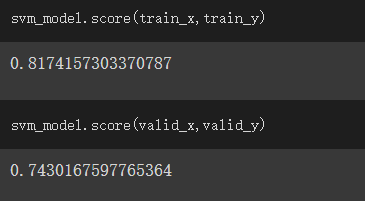
使用model預測結果
輸出CSV檔之後就可以繳上kaggle titanic囉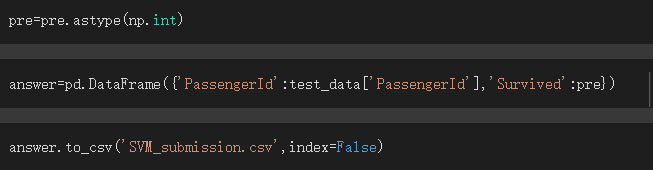
繳交結果
IT_submission 為DNN的訓練結果(前面文章有寫)
SVM_submission 為SVM的訓練結果(就是本文章的結果)
KNN_submission 為KNN的訓練結果 (後面文章會寫)
Kmeans_submission 為Kmeans的訓練結果(後面文章會寫)
此全部都用相同的資料前處理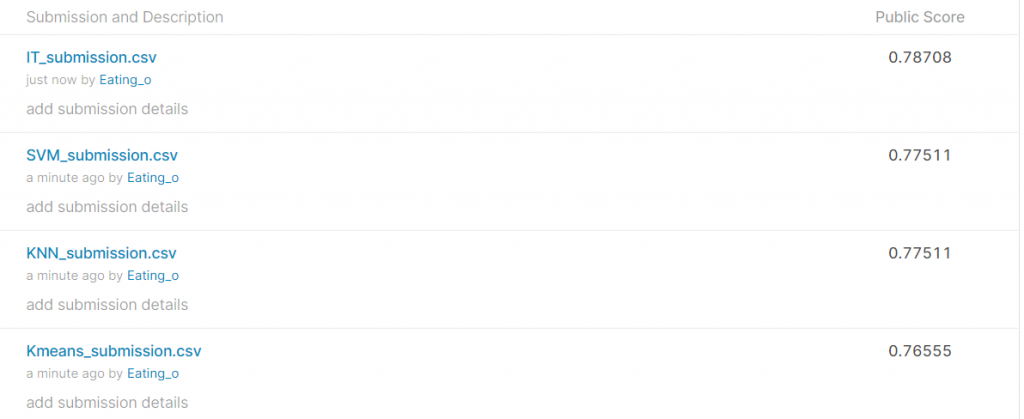
附上程式碼,程式碼我有分過目錄,你可以直接跳到SVM
https://colab.research.google.com/drive/1sQrInNscPzKSMuekyH1Cwz1dYSB9PSNT?usp=sharing

